Robotlar Neden Web Sitelerinde "Ben Robot Değilim" Kutusunu Tıklayamıyor?
Çevrimiçi dünyada, robot olmadığımızı doğrulamanın istenildiği kutularla karşılaşmak yaygın hale geldi. "Ben robot değilim" ifadesini içeren bu kutular, istem dışı aktivitelerden web sitelerini korumak için tasarlanan reCAPTCHA adlı bir sistemin parçasıdır. reCAPTCHA sistemi, kullanıcı kimliklerini doğrulamak ve onların insan mı yoksa bot mu olduğunu belirlemek için birkaç sofistike tekniğe dayanır. Ancak soru devam ediyor: Neden robotlar bu kutuyu basitçe tıklayıp sorun yaşamadan devam edemez? Bu makalede, bunun arkasındaki teknik nedenleri ve bu sistemlerin web sitelerini korumak ve kullanıcı güvenliğini sağlamak için nasıl çalıştığını inceleyeceğiz. CAPTCHA doğrulama sisteminin evrimini, reCAPTCHA'nın nasıl çalıştığını ve sistemin kullanıcı davranışını analiz etmek için kullandığı gizli yöntemleri derinlemesine inceleyeceğiz. Ayrıca, bu sistemlerin gelecekte yapay zekânın ve robotların karmaşık görevleri yerine getirme kapasitesinin artmasıyla karşılaşacağı zorlukları tartışacağız. Amacımız, bu sistemlerin nasıl çalıştığına ve internet güvenliğini sağlamadaki önemine dair kapsamlı bir anlayış sağlamaktır.
Önemli noktaları göster
- reCAPTCHA sistemleri kullanıcı davranışını analiz etmek ve insanları botlardan ayırt etmek için gelişmiş teknikler kullanır, yalnızca bir doğrulama kutusunu tıklamaya dayanmaz.
- CAPTCHA teknolojileri, bozulmuş metinler sunmaktan klik hızları ve fare hareketi yolları gibi web etkileşimlerinin ayrıntılı davranış analizi kullanmaya evrim geçirmiştir.
- Modern reCAPTCHA, fare hareketleri ve tarama geçmişi gibi verileri toplamak ve analiz etmek için gizli tekniklere güvenir, bu da botları doğru bir şekilde algılama yeteneğini artırır.
-
- Botlar genellikle çok hızlı ve doğru hareket eder, bu da sistemin onları tespit etmesi için insani olmayan bir gösterge işlevi görür.
- Yapay zekânın ilerlemesiyle CAPTCHA sistemleri artan zorluklarla karşılaşır, bu da daha derin ve karmaşık doğrulama tekniklerinin geliştirilmesini gerektirir.
- Gelecekteki potansiyel güncellemeler, güvenliği artırmak için yüz tanıma veya yazma desenleri gibi biyometrik verilerin kullanılmasını içerebilir.
- Güvenlik sistemi geliştiricileri, web sitelerini güvenli hale getirme ile kullanıcı gizliliğini koruma arasında sürekli bir denge kurmalıdır.
CAPTCHA Doğrulama Sisteminin Evrimi
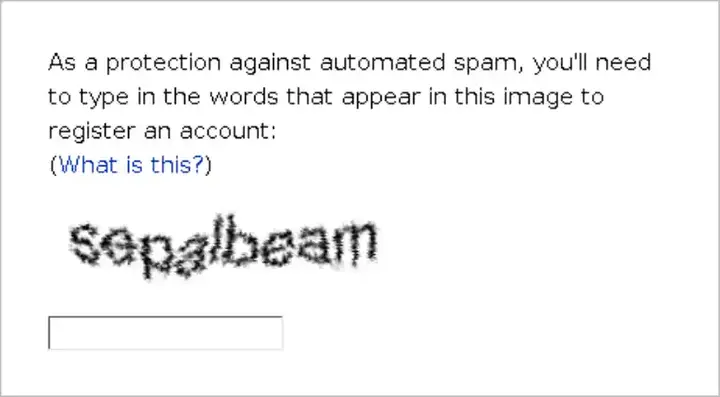
Yıllar içerisinde önemli bir evrim geçirdi. Başlangıçta, testler, botların okumakta zorlandığı bozuk metinler sunmaya dayanıyordu, ancak yapay zekâ ilerledikçe, botlar bu testleri kolayca geçebiliyordu. Sonuç olarak, daha karmaşık doğrulama sistemleri geliştirmek gerekliydi. Google, reCAPTCHA'yı satın alarak botlarla mücadelede yeni bir karmaşıklık ve etkinlik seviyesi ekledi. reCAPTCHA, yalnızca bozuk metinler sunmaya değil, kullanıcı davranışlarını analiz etmeye dayanır. Bu teknoloji, tıklama hızı, fare hareket yolları ve etkileşim zamanlaması gibi birkaç faktörü dikkate alır. Bu evrim sayesinde, geleneksel botlar bu sistemleri aşmakta zorlanmaktadır. Ancak bu, meydan okumanın sona erdiği anlamına gelmez. Yapay zekâ ve robotik teknolojilerdeki ilerlemelere ayak uydurmak için sistemlerin sürekli güncellenmesi gerekmektedir.
reCAPTCHA Sistemi Nasıl Çalışır?

reCAPTCHA sistemi, kullanıcının kutuyu tıklama yeteneğine sadece dayanmamakla kalmaz, aynı zamanda nasıl tıkladığını ve işlem sırasında davranışlarını da izler. Botlar, kutuları tıklamak da dahil olmak üzere görevlerde genellikle insanlardan daha hızlı ve daha etkilidir. Sistem, fare hareket yollarını ve tıklama hızını analiz eder; insanlar genellikle daha yavaş ve daha rastgele hareket eder. Eğer bir tıklama çok hızlı ve doğrudan ise, sistem kullanıcıdan ek bir test tamamlamasını ister, örneğin belirli görüntüleri tanımlamak gibi. Bu ek testler, görüntülerin karmaşıklığı ve üst üste binen görsel faktörlerden dolayı botlar için hala zor olan unsurları tanıma yeteneğine dayanır. Bu teknolojiler, reCAPTCHA'nın insanları ve botları doğru bir şekilde ayırt etmesine olanak tanıyarak, web sitelerini istenmeyen faaliyetlerden korumaya katkıda bulunur.
Gizli Yöntemler ve Kapsamlı Gözetim
Bazı web siteleri artık kullanıcı davranışını çevrimiçi olarak analiz eden ve fare yolları, tarama geçmişi ve çerezler gibi unsurları içeren görünmez doğrulama teknikleri kullanmaktadır. Bu sistemler, insanların mı yoksa botların mı olduğunu belirlemek için mevcut bilgilere dayanarak kullanıcılara puan verir. Bu teknikler gizliliğe müdahaleci görünebilse de pürüzsüz ve güvenli bir kullanıcı deneyimini sağlamaya yardımcı olur. Örneğin, reCAPTCHA Enterprise, kullanıcı kimliğine dair doğru değerlendirmeler sağlamak için geniş bir veri yelpazesine dayanır. Tarama desenleri, içerik etkileşimi ve hatta yazma hızı gibi çeşitli faktörler, kullanıcının gerçek bir insan mı yoksa bot mu olduğunu sağlamak için gerçek zamanda analiz edilir. Bu gelişmiş yöntemler sayesinde, reCAPTCHA kullanıcı deneyimini önemli ölçüde etkilemeden ek bir güvenlik katmanı sağlayabilir.
Doğrulama Sistemlerinin Geleceği ve Zorluklar

Yapay zekânın sürekli ilerlemesiyle, bazı botlar karmaşık Turing testlerini geçmeye başlıyor, bu da mevcut doğrulama sistemleri için ciddi zorluklar yaratıyor. Bu gelişme, insanları ve botları ayırt etmek için Google gibi geliştiricileri daha karmaşık ve etkili çözümler üretmeye zorluyor. Örneğin, doğrulama sistemleri, daha karmaşık şekillerde derin davranış analizi yapmak, yazma desenlerini analiz etmek ve site etkileşimlerinin meydana geldiği bağlamı anlamak için yapay zekayı kullanmak gibi yöntemlere dayanabilir. Bu ilerlemeler, verileri gerçek zamanda analiz etmek, kullanıcı kimliğine dair hassas değerlendirmeler sunmak için derin öğrenme ve sinir ağlarının kullanılmasını içerebilir. Ayrıca, gelecekteki çözümler, ek kimlik doğrulama yöntemleri olarak yüz tanıma veya biyometrik analiz gibi teknolojileri içerebilir. Ancak, bu ilerlemelerle birlikte, kullanıcı gizliliğini koruma ve kişisel verilerin etik olmayan bir şekilde kullanılmamasını sağlama zorluğu gelir. Bu nedenle, güvenlik ve gizlilik arasında hassas bir denge, en iyi sonuçları elde etmek için teknoloji geliştiricileri ve yasama organları arasında sürekli işbirliği gerektirir. Sonuç olarak, doğrulama sistemleri internet güvenliğini sağlamak için gerekli kalır, ancak geleceğin zorluklarıyla yüzleşmek için esnek ve gelişmiş kalmalıdır.

Sonuç olarak, robotların "Ben robot değilim" kutusunu tıklayamamalarının büyülü bir nedeni yoktur; mesele tıklamanın nasıl yapıldığıdır. Mevcut sistemler, insanların rastgele ve yavaş davranışlarını, robotların hızlı ve kesin davranışlarıyla karşılaştırarak analiz eder. Yapay zekâ ilerledikçe, çevrimiçi güvenliği sağlamak için doğrulama sistemlerini her zaman güncellememiz gerekecek.